R言語でヒストグラムを作成できる関数hist()の使い方について解説していく。
なお今回は度数分布を表すヒストグラムを書くことを目的とし、確率密度をプロットするために利用する引数についての説明は省略する。
関数hist()の概要
hist()はその名の通りヒストグラムを描画するための関数だ。
Rに標準搭載されているためパッケージのインストールを必要とせず、扱いやすいのが特徴である。
hist(x, breaks = "Sturges",
freq = NULL, probability = !freq,
include.lowest = TRUE, right = TRUE,
density = NULL, angle = 45, col = NULL, border = NULL,
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,
axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, warn.unused = TRUE, …)
引用元:RDocumentation|graphics (version 3.6.2)|hist: Histograms
https://www.rdocumentation.org/packages/graphics/versions/3.6.2/topics/hist
| 引数 | 意味 |
|---|---|
| breaks | ヒストグラムのbin(棒の幅)を決める。 デフォルトでは\(\log_2 N+1,N=\mbox{サンプルサイズ}\)(Sturgesの公式)。 breaks=seq(min値,max値,binの幅)で調整可能。 |
| main | グラフのタイトル。 |
| xlab | x軸名。 |
| ylab | y軸名。 |
| col | グラフの色。 |
| ylim | y軸の区間。 |
今回はデフォルトで利用できるデータセット”iris”を使う。
これはアヤメ3種のSepal(がく片)とPetal(花弁)のLength(長さ)とWidth(幅)のデータで、各種50件ずつ合計150件のデータで構成されている。
data <- iris
summary(data)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500 1.基本のヒストグラムを書いてみる
以下のコードで基本となるヒストグラムを描画できる。
hist(data$Sepal.Length)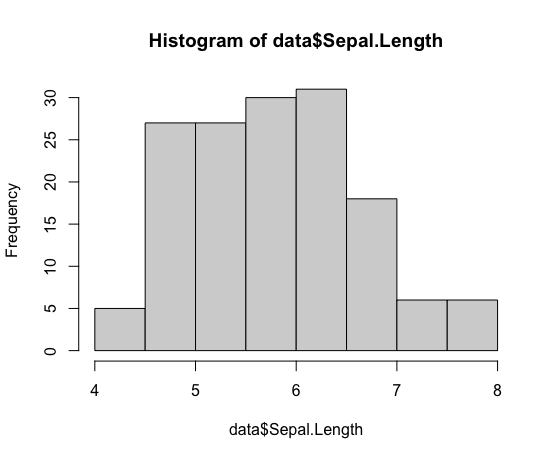
これだけでヒストグラムが出来上がる。
グラフに最低限必要とされるタイトル、軸名称、軸目盛をデフォルトで表示してくれるのは嬉しい点だ。1
2.binの数を変更してみよう
より細かい・粗い粒度で分布をみたい時には引数breaksを変更すれば良い。
hist(data$Sepal.Length,breaks = seq(4,8,0.3))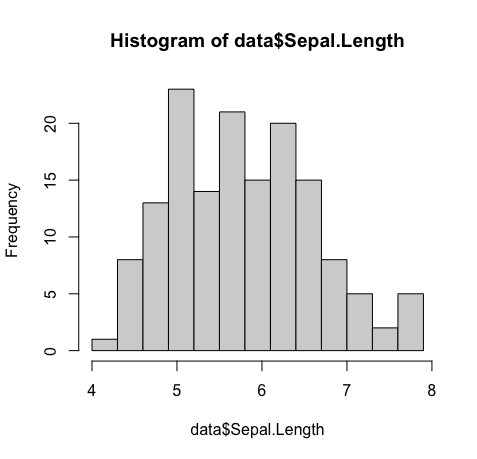
summary関数により、Sepal.Lengthは4.3~7.9の値を取ることが分かっているため、区間を4~8と設定。
なおbreaks内の変数を以下のようにすることで、同様のヒストグラムが描画できる。
trunc/ceilingは切り捨て/切り上げ関数、min/maxは最小値/最大値を取得する関数である2。
hist(data$Sepal.Length,breaks = seq(trunc(min(data$Sepal.Length)),ceiling(max(data$Sepal.Length)),0.2))おまけ.複数のヒストグラムを色分けして、1つのグラフに収めよう。
複数のヒストグラムを同じグラフに収める方法も紹介する。
hist_seq <- seq(0,8,0.5)
hist(data$Sepal.Length,breaks = hist_seq,main = "Histogram of Sepal.Length and Petal.Length",xlab = "length(cm)",ylim = c(0,50),col = '#0080ff')#青色
hist(data$Petal.Length,breaks = hist_seq,col = '#00ff0050',add=T)#緑色+不透明度50%
legend("topright",legend=c("Sepal.Length", "Petal.Length"), col=c("#0080ff", "#00ff00"),pch=15)#凡例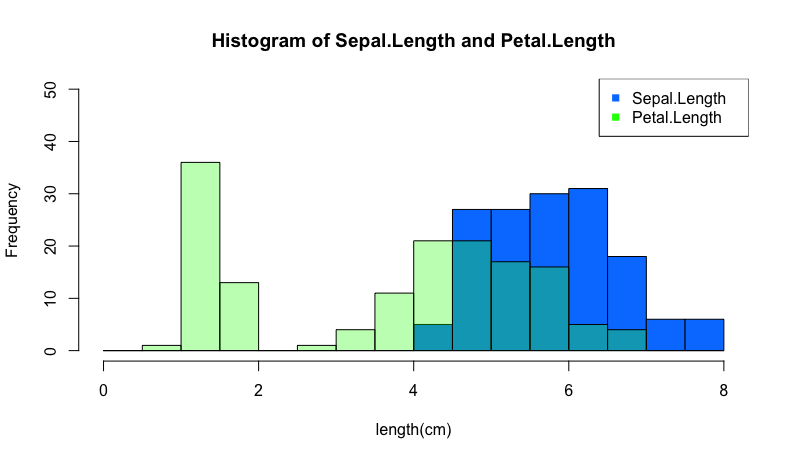
add=Tとすることで、先にプロットした青色のヒストグラム(Sepal.Length)の上に被せるように描画できる。
また6桁のカラーコードの後ろに不透明度2桁を入れることで、複数のヒストグラムを1つのグラフに収めてもデータが見えなくなる心配がない。3
最後に記載したlegendについては、右上に表示した凡例を表示するための関数だ。
本記事では詳細を割愛するが、表示位置、凡例名、色、シンボルを指定している。
異なるデータを同じグラフに表示するとき、凡例がないと混乱を招くため忘れずに記載しよう。
参考:RDocumentation|graphics (version 3.6.2)|legend: Add Legends to Plots
https://www.rdocumentation.org/packages/graphics/versions/3.6.2/topics/legend
- 「タイトルや 軸名は かならず そうびしてください! もっているだけじゃダメですよ!」 ↩︎
- ベタ書きするよりも関数などで処理できる方が
かっこいい適切だと思う反面、私はデータをざっくり見る目的(データクレンジング前の初期調査など)で利用する場合にはベタ書きで対応してしまうことも多い。 ↩︎ - 異なるデータの分布を同時に表示するなら箱ひげ図を利用する手法もあるため、どちらが適切かは目的に応じて検討するのが望ましい。分野や扱うデータにもよる可能性はあるが、私個人の経験で言えば異なる分布を比較する場合は箱ひげ図をよく使っていた記憶(微妙にズレるぐらいの2つを比べるなら便利そうだけど)。
とはいえグラフを重ねるやり方は今後も活用するため、参考として記載させていただく。 ↩︎